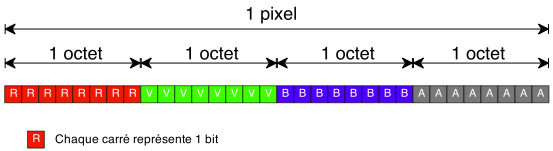
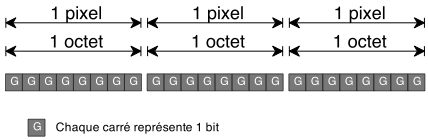
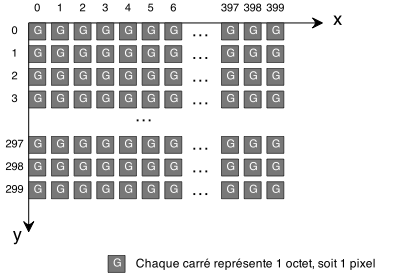
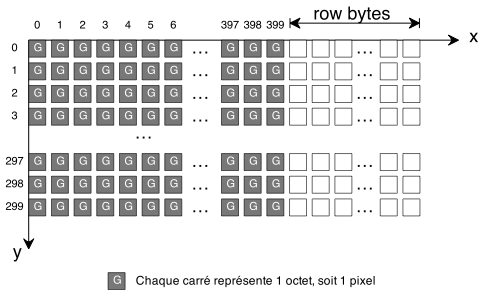
Nous étions restés la fois précédente sur une version un peu lente de notre générateur. Nous allons tenter d'améliorer cela.
Une mise au point s'impose
Je lis fréquemment des gens qui tiennent à peu près ce discours: "Les programmeurs ne tirent pas partie de la puissance des machines, s'ils programmaient en assembleur, les programmes iraient super vite. Ils programment comme des porcs, uniquement pour des raisons financières".
Premièrement, les raisons financières restent de bonnes raisons. Deuxièmement, il faut toujours faire des compromis: programmer efficacement en assembleur est très long, exige des connaissances pointues et le code n'est absolument pas portable, ce qui pose problème quand un logiciel doit être maintenu pendant des années.
Mais surtout, troisièmement, le postulat que les programmes tout-assembleur seraient bien plus rapides est faux !
Dans une application habituelle, 90% du temps est passé dans 10% du code. Cela signifie qu'améliorer ces 10% du code va suffire à accélérer grandement le programme. La bonne stratégie est d'écrire de la façon la plus lisible possible et de n'optimiser que les parties les plus critiques.
L'optimisation… dans l'ordre
- Choisissez les bons algorithmes
C'est le moyen le plus sûr d'accélérer un programme. À quoi bon programmer au plus près de la machine s'il existe un algorithme plus efficace par son principe ?
- Exploitez au mieux le matériel
Utilisez tous les cœurs de votre micro-processeurs, déléguez les traitements à la carte graphique, profitez des instructions vectorielles
- Sachez comment fonctionne votre Unix
C'est le système d'exploitation qui gère les ressources de votre applications, en particulier la mémoire et les fichiers. Ses contraintes peuvent avoir un impact important sur les performances.
- En dernier recours seulement, travaillez sur le bas niveau
Dans certaines applications (jeux, calculs 3D), tailler le code au plus près du microprocesseur reste nécessaire.
Dans tous les cas: ME-SU-REZ !
Optimisez seulement après avoir localisé les sources de lenteurs: elles ne sont pas toujours évidentes. En outre, seules les mesures valident l'efficacité des optimisations.
Mesurons notre appli
Commençons donc par mesurer les temps d'exécution:
Mesure avec Shark
- Sous Xcode, Choisissez l'article du menu Run > Start with Performance Tool > Shark.
- Cliquez sur le bouton Start.
- Une fenêtre apparaît (le chemin de notre exécutable est déjà réglé). Cliquez sur OK.
- L'appli se lance. Redimensionnez la fenêtre continuellement pendant 30 secondes, jusqu'à ce que Shark prenne la main.
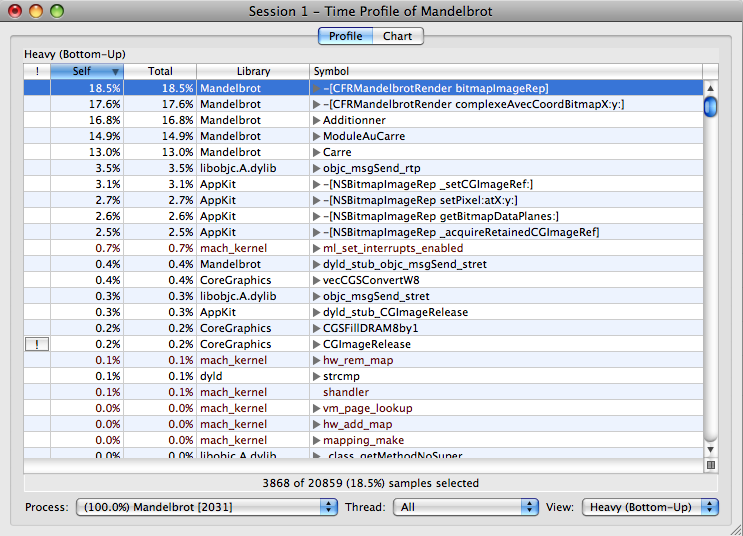
Le résultat n'est pas très surprenant, on trouve en tête nos fonctions qui génèrent l'image. Nous savons où attaquer: ces cinq premières méthodes totalisent plus de 80% du temps d'exécution.
Ensuite, on trouve objc_msgSend_rtp. Il s'agit de la fonction du runtime Objective-C qui permet d'envoyer des messages entre les objets. On peut éventuellement le réduire en envoyant moins de messages…
À vrai dire, ce qui m'étonne sont les 2,7% de setPixel:atX:y:, je pensais que ce serait plus. Il me paraît aussi assez surprenant que _setCGImageRef: apparaisse si haut dans le classement. Voilà pourquoi vous devez mesurer: où les optimisations doivent être faîtes n'est pas toujours évident.
Principe de mesure de Shark
Shark utilise une interruption. Chaque fois qu'elle est déclenchée (toutes les millisecondes, par défaut), Shark note quelle fonction ou méthode est en train d'être exécutée. À la fin, il n'a plus qu'à compter pour établir un classement. Notez qu'il s'agit d'une approche statistique: évaluer le même programme plusieurs fois ne donnera pas les mêmes résultats (les interruptions ne sont pas synchronisées avec le lancement du programme). Il faut admettre une marge d'environ 2%.
Une mesure absolue
L'inconvénient de la mesure avec Shark, c'est qu'elle nous fournit des proportions du temps passé. Ce qui serait intéressant serait d'avoir une mesure du temps de rendu pour mesurer l'amélioration. J'ai donc créé une nouvelle classe, CFMesurePerf pour cela:
#import "CFRMesurePerf.h"
#define IMAGES_A_RENDRE 50
Nous calculons la même image 50 fois de suite. Le temps d'exécution varie: notre programme ne tourne pas tout seul, il y a d'autres processus en parallèle, il faut du temps pour que le système décide de sortir du mode économie d'énergie, etc. . Calculer plusieurs fois permet de lisser les différences.
@implementation CFRMesurePerf
- (id) init
{
if(self = [super init])
{
CFRMandelbrotRender* render = [[CFRMandelbrotRender alloc] init];
[render setLargeurBitmap:1000];
[render setHauteurBitmap:1000];
Nous créons un CFRMandelbrotRender. Il ne sera pas affiché à l'écran; ce qui nous intéresse est son temps de calcul. Nous demandons le calcul d'un million de points.
NSDate* dateDepart = [NSDate date];
// Rendre l'image IMAGES_A_RENDRE fois
int image;
for(image = 0; image < IMAGES_A_RENDRE; image++)
{
[render bitmapImageRep];
}
NSDate* dateFin = [NSDate date];
Nous notons la date de début, rendons les 50 images, puis notons la date de fin.
float secondesEcoulees = [dateFin timeIntervalSinceDate:dateDepart];
int imagesARendre = IMAGES_A_RENDRE;
NSLog(@"%d images rendues en %f secondes.", imagesARendre, secondesEcoulees);
NSLog(@"Moyenne = %f images/s", IMAGES_A_RENDRE/secondesEcoulees);
La différence entre les deux dates nous fournit la durée du calcul. Nous pouvons en déduire la moyenne.
}
return self;
}
@end
J'ai choisi d'instancier cette classe à partir de MyDocument.xib. Je vous laisse faire.
Dorénavant, lorsque le programme se lance, il va calculer 50 images. C'est assez long, soyez patients! Il faut plus d'une minute sur mon G5, avec une moyenne de 0,79 images/seconde.
Appels à complexeAvecCoordBitmapX:y:
Passons maintenant à une optimisation de l'algorithme. La méthode -[complexeAvecCoordBitmapX:y] est actuellement appelée pour chaque point. Ce n'est absolument pas nécessaire. Il nous suffit de calculer de combien il faut incrémenter les coordonnées pour passer d'un point à un autre du plan.
Ainsi:
incrementX = (dernierPoint.reel - premierPoint.reel) / largeurBitmap;
incrementY = (dernierPoint.imag - premierPoint.imag) / hauteurBitmap;
Nous obtenons alors la méthode de rendu suivante:
// Créer la bitmap
NSBitmapImageRep* bitmapRep = [[NSBitmapImageRep alloc]
initWithBitmapDataPlanes:NULL
pixelsWide:largeurBitmap
pixelsHigh:hauteurBitmap
bitsPerSample:8
samplesPerPixel:1
hasAlpha:NO
isPlanar:NO
colorSpaceName:NSDeviceWhiteColorSpace
bytesPerRow:0
bitsPerPixel:8];
// Déterminer les incréments des coordonnées
Complexe_t premierPoint, dernierPoint;
premierPoint = [self complexeAvecCoordBitmapX:0 y:0];
dernierPoint = [self complexeAvecCoordBitmapX:largeurBitmap-1 y:hauteurBitmap-1];
Calculer les coordonnées des points extrêmes se fait encore avec notre bonne vieille méthode.
double incX = (dernierPoint.reel - premierPoint.reel) / largeurBitmap;
double incY = (dernierPoint.imag - premierPoint.imag) / hauteurBitmap;
Voir la formule plus haut.
// Calculer l'ensemble de Mandelbrot:
// Parcourir tous les points de la bitmap
double x, y;
Complexe_t c = premierPoint;
c est maintenant initialisé avec le premier point.
for(x = 0; x < largeurBitmap; x++)
{
for(y = 0; y < hauteurBitmap; y++)
{
// Initialiser z[0]
Complexe_t z = {0.0, 0.0};
NSUInteger n;
for(n=0; n < MAX_ITERATIONS; n++)
{
// z[n+1] = z[n+1]^2 + c
z = Additionner(Carre(z), c);
// La suite diverge si |z| > 2
if(ModuleAuCarre(z) > 4.0)
break;
}
// Donner le niveau de gris au pixel
NSUInteger nuance = n * 255 / MAX_ITERATIONS;
[bitmapRep setPixel:&nuance atX:x y:y];
c.imag += incY;
Nous incrémentons donc l'ordonnée ici.
}
c.imag = premierPoint.imag;
c.reel += incX;
Il ne faut pas oublier de replacer l'ordonnée en haut du plan. Ensuite, nous incrémentons l'abscisse.
}
[bitmapRep autorelease];
return bitmapRep;
Au niveau des performances, j'atteins maintenant les 1,06 images/s, soit un gain de 34%. Pas mal !
Placer les fonctions mathématiques "en ligne"
En mettant un compteur dans la boucle for, vous sauriez qu'elle est exécutée 4 239 692 fois. Autant dire que tout ce qui s'y trouve est critique. Or, un appel de fonction réserve de la mémoire sur la pile et copie les paramètres. Il ne s'agit pas d'opérations particulièrement lourdes, mais quand on le fait 4 millions de fois, cela devient très significatif. Nous n'allons donc plus faire d'appels aux fonctions, mais les incorporer:
Complexe_t z = {0.0, 0.0};
Complexe_t zCarre;
NSUInteger n;
for(n=0; n < MAX_ITERATIONS; n++)
{
// z[n+1] = z[n+1]^2 + c
// Mettre z au carré
zCarre.reel = z.reel*z.reel - z.imag*z.imag;
zCarre.imag = 2.0 * z.reel * z.imag;
// Ajouter c
z.reel = zCarre.reel + c.reel;
z.imag = zCarre.imag + c.imag;
// La suite diverge si |z| > 2
if( (z.reel*z.reel + z.imag*z.imag) > 4.0)
break;
}
Le résultat est sans appel: il ne faut plus que 24 s pour rendre les 50 images, soit une moyenne de 2,06 images/s — quasiment deux fois plus vite. La méthode est par contre moins lisible: c'est habituel dès que l'on optimise. Il s'agit toujours d'un compromis entre la vitesse et la maintenabilité du code.
La suite
Il nous reste une dernière optimisation à faire, mais comme elle nécessite des explications, je m'arrête là pour cette fois. À bientôt.
Le projet XCode complet à télécharger.
Renaud Pradenc
Céroce.com

 Quand on appuie sur la touche Contrôle, le curseur de la souris doit se transformer en flèches. Ceci, dès que le pointeur se trouve dans la vue.
Quand on appuie sur la touche Contrôle, le curseur de la souris doit se transformer en flèches. Ceci, dès que le pointeur se trouve dans la vue. Sinon, si le bouton n'est pas appuyé, le curseur est une main ouverte.
Sinon, si le bouton n'est pas appuyé, le curseur est une main ouverte.  S'il est appuyé, une main fermé.
S'il est appuyé, une main fermé.
 Cependant, les détails ne sont alors plus très présents. C'est parce que nous avons fixé le nombre d'itérations maximales trop bas. Heureusement, nous permettrons prochainement de modifier ce seuil.
Cependant, les détails ne sont alors plus très présents. C'est parce que nous avons fixé le nombre d'itérations maximales trop bas. Heureusement, nous permettrons prochainement de modifier ce seuil.