Développement Mac et iPhone
Générateur d'images fractales (6)
03032009 Author: Renaud Pradenc In: Pas à pasNous continuons aujourd'hui l'optimisation de la génération de l'image.
Les bitmaps
J'ai vaguement expliqué ce qu'était une bitmap, me contentant de dire qu'il s'agissait d'une grille de pixels. Intéressons-nous à leur organisation en mémoire.
32 bits par pixel
Utiliser 32 bits pour stocker les composantes d'un pixel est des plus classiques:
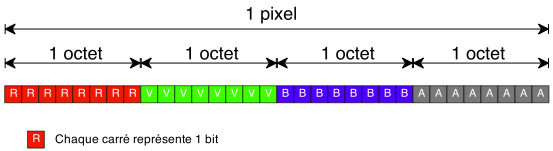
Chaque composante utilise un octet, et peut donc contenir une valeur de 0 à 255. Doser les quantités de rouge, de vert et de bleu permet de choisir la teinte du pixel; la composante alpha correspond à l'opacité du pixel.
256 niveaux de gris
Notre générateur utilise une bitmap en 256 niveaux de gris:
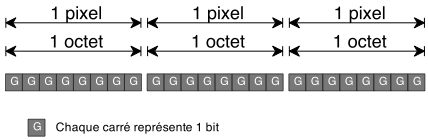
C'est le même principe: la valeur de l'octet fournit la nuance; 0 correspond au noir et 255 au blanc, voilà pourquoi nous utilisons la ligne:
NSUInteger nuance = n * 255 / MAX_ITERATIONS;
pour déterminer la nuance du pixel calculé.
Organisation en mémoire
Voyons maintenant la relation entre les pixels et les coordonnées:
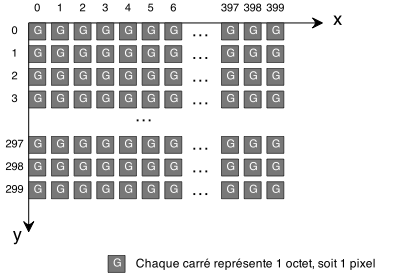
Dans cet exemple, la bitmap mesure 400 pixels de large et 300 de haut. Ce qui est intéressant, c'est que les pixels se suivent en mémoire. Ainsi, si nous disposons de l'adresse à laquelle est stockée la bitmap, adresseBitmap:
- Le pixel de coordonnées (0,0) se trouve à l'adresse
adresseBitmap. - Le dernier pixel de la première ligne (399, 0) se trouve à l'adresse
adresseBitmap + 399(puisqu'un pixel prend exactement un octet). - Le premier pixel de la deuxième ligne (0, 1), se trouve à l'adresse
adresseBitmap + 400. - etc.
En généralisant nous obtenons:
adressePixel = adresseBitmap + (400 * y) + x
ou en généralisant d'avantage:
adressePixel = adresseBitmap + (largeurBitmap * y) + x
Il nous suffit d'écrire la nuance à cette adresse pour modifier le point. Vous devez maintenant avoir une bonne idée du fonctionnement de la méthode -[NSBitmapImageRep setPixel:atX:y];
Row Bytes
À vrai dire, j'ai simplifié la figure précédente, en omettant un détail. Voici une figure plus juste:
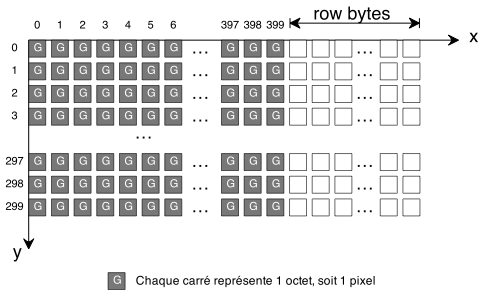
En effet, pour des raisons de performances, des octets inutilisés (row bytes) sont ajoutés à la fin de chaque ligne. Ils servent à aligner la bitmap en mémoire. On ne connaît pas leur nombre a priori: cela dépend de plusieurs paramètres.
Toujours est-il qu'il faut en tenir compte.
L'optimisation
Dans notre boucle de rendu, il ne nous reste plus grand chose que nous puissions améliorer si ce n'est cette ligne:
[bitmapRep setPixel:&nuance atX:x y:y];
Cette méthode est tout de même appelée un million de fois (pour notre rendu en 1000 x 1000 pixels). Les bénéfices attendus en écrivant directement dans la bitmap sont les suivants:
- Ne plus appeler la méthode
[setPixel:atX:y:]. Les appels de méthodes sont encore plus lents que les appels de fonctions. Nous ferons entre-autres l'économie de l'exécution de la fonctionobjc_msgSend_rtp(). - La méthode
[setPixel:atX:y:]est forcément plus compliquée qu'un écriture directe dans la bitmap, ne serait-ce que par son côté généraliste. De plus, si vous vous rappelez l'article précédent, Shark listait des appels aux méthodes
-[NSBitmapImageRep _setCGImageRef:]
-[NSBitmapImageRep getBitmapDataPlanes:]
-[NSBitmapImageRep _acquireRetainesCGImageRef]
Je pense que ceci va nous permettre de nous en passer.
Le code
Inverser les énumérations des x et y
À cause de la manière dont est stockée la bitmap, il est nécessaire les énumérations de x et y :
for(y = 0; y < hauteurBitmap; y++)
{
for(x = 0; x < largeurBitmap; x++)
{
…
c.reel += incX;
}
c.reel = premierPoint.reel;
c.imag += incY;
}
Adresser la bitmap
Avant le calcul:
// Obtenir la bitmap
unsigned char* bitmapPtr = [bitmapRep bitmapData];
On demande l'adresse de la bitmap.
unsigned int rowBytes = [bitmapRep bytesPerRow] - largeurBitmap;
La méthode [bitmapRep bytesPerRow] renvoie le nombre d'octets utilisés pour stocker une ligne. Comme nous savons que largeurBitmap octets sont utiles, nous en déduisons le nombre d'octets d'alignement (rowBytes).
for(y = 0; y < hauteurBitmap; y++)
{
for(x = 0; x < largeurBitmap; x++)
{
…
// Donner le niveau de gris au pixel
*bitmapPtr = n * 255 / MAX_ITERATIONS;
Nous conservons la formule du calcul de la nuance, que nous écrivons dans la bitmap à l'adresse du pixel courant.
bitmapPtr++;
Puis nous passons au pixel suivant.
c.reel += incX;
}
c.reel = premierPoint.reel;
c.imag += incY;
bitmapPtr += rowBytes; // Sauter les octets inutilisés en fin de ligne
À la fin de chaque ligne, nous sautons les octets inutilisés.
}
Résultat
50 images rendues en 12.864695 secondes.
Moyenne = 3.886606 images/s
Nous tournons aux alentours de 4 images/s. Je vous rappelle que la première mesure donnait 0,79 images/s… la vitesse a été multipliée par 5 !
Nous arrivons aux limites de ce que nous pouvons ainsi optimiser. Nous allons nous arrêter là.
Et si ce n'était que le début ?
Améliorer la vitesse demanderait maintenant de recourir à des astuces.
Voici une idée: vous pouvez remarquer que deux pixels qui se suivent sont très souvent de la même nuance. On pourrait ne calculer qu'un pixel sur deux:
- Si le pixel n°3 n'est pas de la même nuance que le pixel n°1, alors on calcule le pixel 2
- Sinon, on lui donne la nuance du pixel 3.
On ne manquerait que des variations brusques (<1 pixel), peu perceptibles.
Cependant, tout cela est sans intérêt, parce que la vraie façon d'améliorer la vitesse est de déléguer le calcul… à la carte graphique! Je crois que n'importe quelle carte est aujourd'hui capable de faire ce calcul en temps réel. Ce sera peut-être pour une prochaine fois (quand j'aurais appris à me servir d'OpenGL Shading Language). En attendant, l'application est utilisable. Nous allons pouvoir nous balader dans l'ensemble de Mandelbrot.
À bientôt pour la suite.
Le projet XCode complet à télécharger.
Renaud Pradenc
Céroce.com